인프런 스프링 입문(jpa와 aop)
이 포스트는 인프런 김영한님의 강의 및 자료를 사용합니다
JPA
이전 글에는 JdbcTemplate을 이용하여 간단한 코드로 Datebase를 사용할 수 있었다.
하지만 JdbcTemplate을 이용하여도 SQL코드는 직접 짜야했다. 이를 보완하기 위해서 JPA를 사용한다.
JPA를 사용하면 기존의 반복 코드, 기본적인 SQL도 JPA가 직접 만들어서 실행해준다. 또한, 객체 중심의 설계가 가능하고 개발 생산성을 크게 높일 수 있다.
JPA를 사용하기 위해서는 기본적으로 gradle파일에 라이브러리를 추가해주어야 한다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
}
또한, application.properties파일에도 설정을 추가해주어야 한다.
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=none
show-sql : JPA가 생성하는 SQL을 출력한다.
spring.jpa.hibernate.ddl-auto : JPA는 테이블을 자동으로 생성하는 기능을 제공하는데 none, create, update등으로 기능을 끄거나 테이블을 만들고, 업데이트하도록 설정할 수 있다.
설정이 완료되었으면, 이제 Entity매핑을 해준다. 데이터베이스에 만들고 싶은 객체에 어노테이션을 붙여주면 된다.
여기서는 회원가입과 회원조회가 주된 기능이므로 Member객체에 추가해준다.
@Entity
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name
이렇게 Entity를 추가하고 실행을 하면 sql로그가 찍히게 되고, 데이터베이스에 Member테이블이 생성된다.
@Id는 primary key라는 것을 나타내고, @GeneratedValue는 키의 자동 생성 전략을 위해 사용된다.
그리고 JpaRepository를 만들어준다.
public class JpaMemberRepository implements MemberRepository {
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
public Member save(Member member) {
em.persist(member);
return member;
}
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
public List<Member> findAll() {
return em.createQuery("select m from Member m", Member.class)
.getResultList();
}
public Optional<Member> findByName(String name) {
List<Member> result = em.createQuery("select m from Member m where
m.name = :name", Member.class)
.setParameter("name", name)
.getResultList();
return result.stream().findAny();
}
}
위의 코드를 보면 알 수 있듯이, JPA를 사용하기 위해서는 EntityManager가 필요하다.
EntityManager는 JPA에서 엔티티의 관리와 데이터베이스와의 상호 작용을 중재하고 관리하는 주요 인터페이스다.
persist(member): 주어진 엔티티를 영속성 컨텍스트에 저장. 즉, 데이터베이스에 저장된다.
find(Member.class, id): 주어진 엔티티 클래스와 기본 키를 사용하여 엔티티를 검색한다. 데이터베이스에서 해당 엔티티를 조회하여 반환한다.
추가적으로, JPA를 통한 데이터 변경을 할 때에 @Transactional을 사용해야 한다. 런타임 예외가 발생하면 롤백하여 데이터를 보존시켜주기 때문이다.
마지막으로 스프링 설정을 변경한다.
@Bean
public MemberRepository memberRepository(){
return new JpaMemberRepository(em);
}
Spring Data JPA
스프링 부트와 JPA만 사용해도 개발 생산성이 많이 증가하고, 개발해야할 코드도 줄어든다. 여기에 스프링 데이터 JPA를 사용하면,
리포지토리에 구현 클래스 없이 인터페이스 만으로 개발을 완료할 수 있다. 그리고 반복 개발해온 기본 CRUD 기능도 스프링 데이터 JPA가 모두 제공한다.
따라서 핵심 비즈니스 로직을 개발하는데 집중할 수 있습니다.
실무에서 관계형 데이터베이스를 사용한다면 스프링 데이터 JPA는 이제 선택이 아니라 필수 이다.
기존의 길고 복잡했던 코드가 Spring Data JPA를 사용하면 아래와 같이 줄어들게 된다.
public interface SpringDataJpaMemberRepository extends JpaRepository<Member, Long>, MemberRepository {
Optional<Member> findByName(String name);
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository);
}
기존에 직접 짜야 했던 save, findAll, findById같은 메서드들이 기본적으로 내장되어 있기 때문이다!
AOP(Aspect-Oriented Programming)
Aspect-Oriented Programming: 특정 관심사를 모듈화하고 재사용하기 위한 프로그래밍 기법
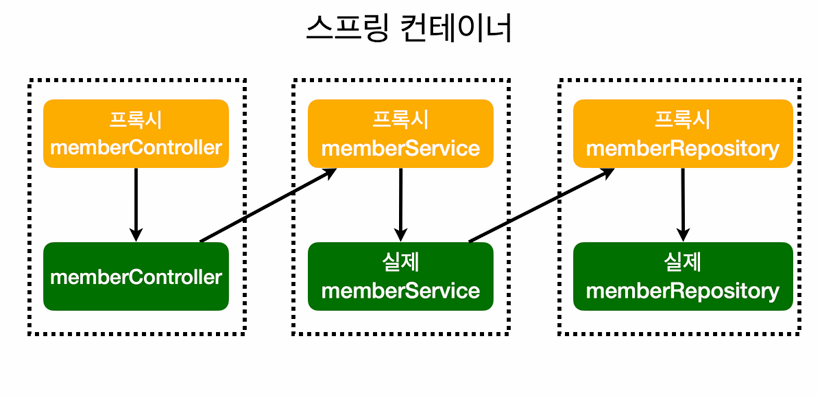
AOP를 설명하기 위해서 모든 메서드의 호출 시간을 출력해야하는 상황이라고 가정하겠다.
메서드가 한 가지나 두 가지라면, 모든 메서드에 로직을 추가하면 된다.
하지만 메서드가 몇 백개, 혹은 몇 천개라면? 모든 메서드에 추가하기 위해서는 많은 시간이 필요하고 효율적이지도 않다.
따라서 이런 상황에 AOP를 사용한다.
@Component
@Aspect
public class TimeTraceAop {
@Around("execution(* hello.hellospring..*(..))")
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
System.out.println("START: " + joinPoint.toString());
try {
return joinPoint.proceed();
}
finally {
long finish = System.currentTimeMillis();
long timeMs = finish - start;
System.out.println("END: " + joinPoint.toString()+ " " + timeMs + "ms");
}
}
@Component, @Aspect: 스프링 빈으로 등록되도록 하고, 애스펙트 역할을 한다는 것을 나타낸다다.
@Around("execution(* hello.hellospring..*(..))"): 적용할 곳을 지정한다. 여기서는 hello.hellospring 패키지와 하위 패키지에 있는 모든 메서드에 지정
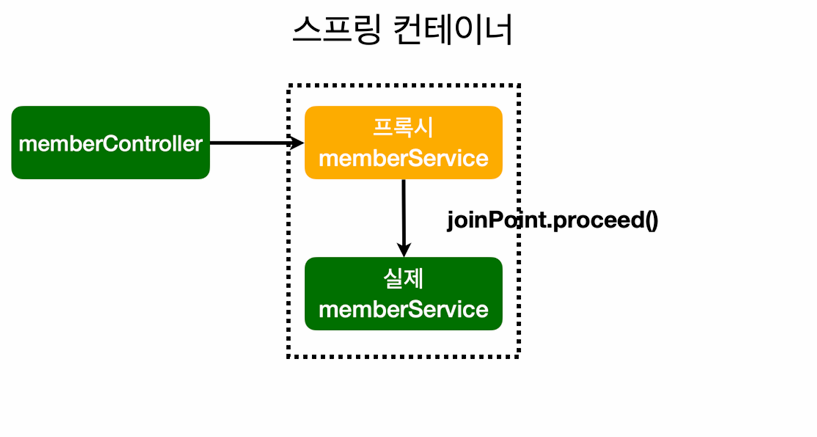
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable: ProceedingJoinPoint 객체를 인자로 받는 시간 측정 메서드 호출
return joinPoint.proceed(): proceed() 메서드를 호출하여 실제 메서드의 실행을 진행합니다.
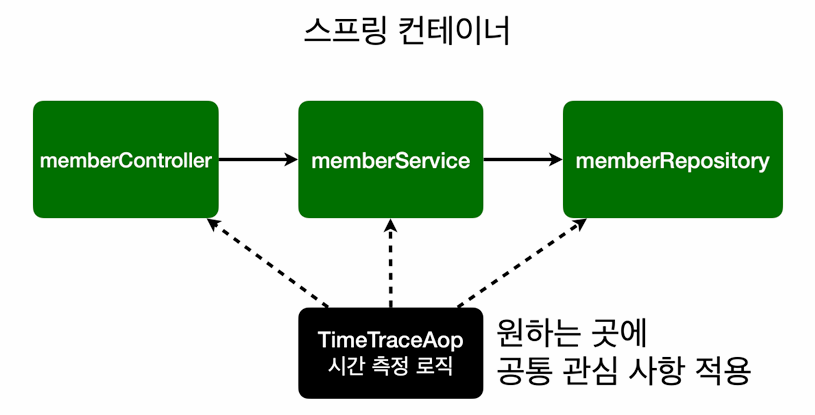
AOP를 통하여..
회원가입, 회원 조회등 핵심 로직과 시간 측정 로직을 분리
핵심 로직을 수정하지 않고 시간 측정 가능
원하는 적용 대상 선택 가능